I couldn't resist connecting the web site tag cloud terms to people associated with those terms to a person's hypertree.
Here it is... PPPeople PPPowered version Alpha 0.1 (yes there are bugs and interface issues but it's still lots of fun).
Wednesday, 31 March 2010
Tuesday, 30 March 2010
My very first Hyperforest
So today I decided to look at little deeper at WHAT I want to plot on a Hypertree anyway. It's quite a difficult question. The purpose of all this, ultimately, it to be a browsing experience (not a reporting one) so I don't care if the diagram is an accurate reflection all that matters is that if it is accurate enough to flush out some interesting connections.
The diagram should look plausible but then have oddities in. So.... today I took a simplistic view that went...
The end results are a quite good...
Gustav Delius - a mathematician who is involved in lots of web projects looks like this...

Trevor Sheldon - the Deputy Vice Chancellor looks like this...

Sue Hodges - Educator definitely not into social media self-promotion looks like this...

It's looking promising. The pictures look great... now if I can just fathom what they mean I'll be laughing.
Tomorrow I need to research talking to the ZODB and how to make custom object types in Plone so that I can take this data and integrate it into a social networking site we're running.
The diagram should look plausible but then have oddities in. So.... today I took a simplistic view that went...
- What web documents is someone mentioned in
- What topics are associated with those documents
- What terms are those documents associated with (and which topics)
- Who else is on the documents that have those terms
The end results are a quite good...
Gustav Delius - a mathematician who is involved in lots of web projects looks like this...

Trevor Sheldon - the Deputy Vice Chancellor looks like this...

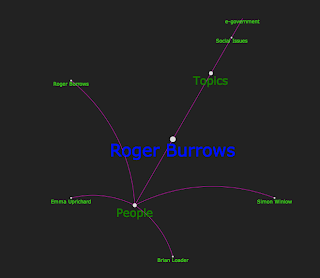
Roger Burrows - Sociologist who might be said to have concerns about technology and privacy (forgive me if I'm wrong Roger)... looks like this...

Sue Hodges - Educator definitely not into social media self-promotion looks like this...

It's looking promising. The pictures look great... now if I can just fathom what they mean I'll be laughing.
Tomorrow I need to research talking to the ZODB and how to make custom object types in Plone so that I can take this data and integrate it into a social networking site we're running.
Monday, 29 March 2010
My Very First Hypertree
Sometimes, in fact most of the times for me, I find it difficult to work with certain concepts until I can see them. I began today by making the templates that could just show the data I have gathered from Open Calais so that I could get a feel for what's there.
And just now I started adding a little Hypertree magic. Here's some of the data displayed quite simply.


I'm pleased that I'm able to display something. I now need to work on the user interface and add a nice search interface and popup areas for "people information" and maybe to be able to load more data as you click on a node.
I also now need to think about which connections between people are most important and perhaps how to structure the industry terms.
And just now I started adding a little Hypertree magic. Here's some of the data displayed quite simply.

The funny shape makes me realise that I've made a completely arbitrary three-way split of pages, people and terms and that I need to make it build its hierarchy dynamically. Ooh that one hurts.
It looks even stranger when someone happens to have been in lots of pages about meeting minutes. Here's Jo Casey as a Hypertree.

I'm pleased that I'm able to display something. I now need to work on the user interface and add a nice search interface and popup areas for "people information" and maybe to be able to load more data as you click on a node.
I also now need to think about which connections between people are most important and perhaps how to structure the industry terms.
This Week's Plan
My plans for this sprint are to create a navigable interface for the data Open Calais has returned that focusses on people and connections between people. To begin with this might just be "people pages" or an A to Z page but I also was to quickly start using a few lovely visualisations.
I then want to host this data on a site that people can play with (and into a subversion repository). I will initially use Django simply because I'm very familiar with it but the intention is that this will add data to a Cyn.in (or Plone site) so I have bought a book on Plone development so I can start thinking about saving data to the ZODB...
So that I can start simply and learn how the ZODB works, the plan is to...
Slight concern: This sort of means that I'll be splitting my direction... one will be looking at visualisation in Django/MySQL the other is looking at data manipulation and integration within Cyn.in (the environment that will ultimately host this data). I'm hoping that once I have got to the end of the visualisation experimentation and the Cyn.in integration work I will be able to pull the two neatly together somehow.
Visualisation Tools
Infovis looks simple enough and perfect for what I need. I particularly like the Hypertree thing (shown below). Here Jeni has taken some government open data about burglary and shown it on a hypertree... brilliant!

The yFiles library has aGraph viewer component but it seems too complete, and it's not as black (which is cool).

Protovis has some very nice display options, I may come back to this later.

I then want to host this data on a site that people can play with (and into a subversion repository). I will initially use Django simply because I'm very familiar with it but the intention is that this will add data to a Cyn.in (or Plone site) so I have bought a book on Plone development so I can start thinking about saving data to the ZODB...
So that I can start simply and learn how the ZODB works, the plan is to...
- Create a crawler for events that saves regular "Events" objects into the ZODB.
- Create a new content type for "Places". This may have a lat/long and in the long term should be displayed on a map.... maybe on an iPhone. This is a bit more involved
- Create an RSS or RDF grabber Product so that I can integrate people, places, concepts etc with other linkeddata sources... if only to grab an image that represents York the city.
Slight concern: This sort of means that I'll be splitting my direction... one will be looking at visualisation in Django/MySQL the other is looking at data manipulation and integration within Cyn.in (the environment that will ultimately host this data). I'm hoping that once I have got to the end of the visualisation experimentation and the Cyn.in integration work I will be able to pull the two neatly together somehow.
Visualisation Tools
Infovis looks simple enough and perfect for what I need. I particularly like the Hypertree thing (shown below). Here Jeni has taken some government open data about burglary and shown it on a hypertree... brilliant!
The yFiles library has aGraph viewer component but it seems too complete, and it's not as black (which is cool).
Protovis has some very nice display options, I may come back to this later.
Both Raphael and Processing look extremely powerful (go look at the examples) but I will come back to them later once I've done the simple(r) stuff.
One of the lessons learned from the project already is that once you get lots of people working in an open environment that the "Activity Stream" soon resembles a fire-hose of "too much" information. This suggests that the Home Page of any collaborative environment needs to think about displaying aggregate data or visualisations rather than actual data as a way to make the Home Page useful. So it's going to be interesting to try and find novels ways of displaying what for the most part will be conversations.
Saturday, 27 March 2010
Sprint 1, it works
So having crawled the sites, mangled the data... some very simple code...
from djangocalais.models import *
def related_people(name):
es = Entity.objects.filter(name__icontains=name)[0]
cds = CalaisDocument.objects.filter(entities=es)
for cd in cds:
for e in cd.entities.all():
if e.type.name == "Person":
print e.name , ">", cd.__unicode__()
m.related_people("Alastair Fitter")

from djangocalais.models import *
def related_people(name):
es = Entity.objects.filter(name__icontains=name)[0]
cds = CalaisDocument.objects.filter(entities=es)
for cd in cds:
for e in cd.entities.all():
if e.type.name == "Person":
print e.name , ">", cd.__unicode__()
m.related_people("Alastair Fitter")
... produces this....

This is what I like.... Artificial Intelligence for Dummies. I can't wait to slap an interface on this... Now to brush up on some jQuery.
Friday, 26 March 2010
Sprint 1 Done!

York University's web site has been crawled. The data was then manipulated (or added to) using Open Calais - although I still have to leave that cooking a while longer. And then using the Google Visualisation API I created a tag cloud of what are called the top "social tags" for the semantic information.
The entities returned look really interesting. I need to find out how they relate to each other and how I can find connections between peoples.

The next step is to clean up the code. Make it semi-functional so at very least you can explore the data and then put it into Google Code ... with some instructions! Which will look something like this...
1. Install Django and dependencies
2. crawl (http://www.york.ac.uk)
3. analyze()
4. ./manage.py runserver
What a week...
Thursday, 25 March 2010
Python Crawling Tools
I have been here before, here in this case being in a place where I think, "Surely someone has written a fantastic python crawler that is easy to use and extend that is open source". They may have done, but I can't find it.
My particular problem is this. I want it to be easy to use, something like this would be nice...
from crawler import Crawler
class myCrawer(Crawler):
def handle(self, url, html):
#do_something_here
c = myCrawler(url="http://wherever.com")
c.crawl_type = "nice"
c.run( )
... and also, I'd like it to well designed enough not to run out of memory, well documented, know about the strange unicode formats that live out there on the web, to open too many sockets, to do the right thing when a URL times out... and hey to be quick it probably should be threaded to boot.
After days (and days) of downloading and trying crawlers out there have been some worth noting.
My particular problem is this. I want it to be easy to use, something like this would be nice...
from crawler import Crawler
class myCrawer(Crawler):
def handle(self, url, html):
#do_something_here
c = myCrawler(url="http://wherever.com")
c.crawl_type = "nice"
c.run( )
... and also, I'd like it to well designed enough not to run out of memory, well documented, know about the strange unicode formats that live out there on the web, to open too many sockets, to do the right thing when a URL times out... and hey to be quick it probably should be threaded to boot.
After days (and days) of downloading and trying crawlers out there have been some worth noting.
...but I have also tried crawl-e, creepycrawler, curlspider, flyonthewall, fseek, hmcrawler, jazz-crawler, ruya, supercrawler, webchuan, webcrawling, yaspider and more! All of these are rubbish...
The problem is this. It IS possible to write a crawler in 20 or so lines in python that will work... except it won't. It won't handle pages that redirect to themselves, it won't handle links that are ../../ relative, it won't be controllable in any way.
My problem with the two "best contenders" was this. Firstly, HarvestMan, no matter how hard I configure it, always saves the crawled pages to disk. I had this problem in 2006ish, I still have it today. Arnand (lovely guy) the developer has rolled in many of my change requests since then so that the pseudo code above is almost a reality, but only almost. HarvestMan still is a front-runner if just because of the thought that has gone into the configuration options.
Scrapy looked very cool too, but it seems more geared towards getting specific data from known pages, rather than wandering around the web willy nilly. I would have to create my own crawler within Scrapy. I will maybe come back to this but in general, armed with python and a few regular expressions you can't half get a lot done.
So, in my attempt to get "round the loop" once, that is, to a. gather some data from a few sites (namely, the University of York's sites), b. manipulate it in some way (in this case, pump it at Open Calais and see what we get back... poor man's artificial intelligence) and then c.present it ( maybe as a tag cloud, or something more fancy if I have time) I needed a crawler that was very simple to use.
So ...
a. Despite wanting to use an "off the shelf" crawler. I found a crawler that almost worked and hacked it until it worked. It's not threaded, it's not clever but it does the job.
I had to do some hand pruning to look at the mime-types of the pages returned, and remove Betsie pages (of which there were thousands)... but I will try and roll that back into the crawler.
b. I found a Django application called django_calais, which after adding the last line to my Page model, like this...
class Page(models.Model):
url = models.URLField(unique=True, null=False, blank=False, db_index=True)
title = models.CharField(max_length=300, null=True, blank=True)
crawl_date = models.DateTimeField(default=datetime.now)
html = models.TextField()
type = models.CharField(max_length=100, null=True, blank=True)
size = models.IntegerField(null=True, blank=True)
calais_content_fields = [('title', 'text/txt'), ('url', 'text/html'), ('html', 'text/html')]
... I could then run....
def analyze():
pages = Page.objects.filter(type="text/html")
for page in pages:
print page.__unicode__(), page.url
try:
CalaisDocument.objects.analyze(page, fields= [('title', 'text/txt'), ('url', 'text/html'), ('html', 'text/html'),])
except Exception, err:
print err
.... and have my Calais application be populated with People, and Organisations and Companies and Facilities etc. all of which are related back to my Page model.
I haven't got to presentation stage yet, the Calais analyzer is still running, BUT after get quite anxious about spending too long looking for an adequate crawler, the semantic bit has already proven itself. So maybe tomorrow I will be able to present some data...
And then I'd better check it in to a repository or something.
Monday, 22 March 2010
Review of Python Crawling Tools
http://www.ohloh.net/p/WenChuan
Web crawlers are funny things. I have had a little experience of working with web crawlers in the past with a mixed set of results. Many were too difficult to configure or simply not robust enough. At this stage of the project, I would ideally like a crawler that is easy to adapt and yet trust-worthy enough to be able to set it running and leave it.
Imagining that I don't want to crawl very large portions of the internet, instead looking just to work with small corners I will be happy with something simple. Worth trialling are alternatives to "doing it yourself", such a Yahoo Pipes and the 80legs.com crawling service as well as Yahoo Boss search engine builder. Whenever possible I will consider using these tools, simply because of the time needed to crawl for data.
My preferred language is python but I wonder if there is a more web-centric language to think about? I vaguely remember Rebol as having URLs as base types. Maybe Rebol is worth exploring.
I started by looking at a list of python crawlers at Ohloh http://www.ohloh.net/p?sort=users&q=python+crawler and from these tested these....
Testing Notes...
Ruya (Not bad, has before_crawl and after_crawl functions that you overshadow)
Mechanize (Kind of browser simulation - including form filling)
Crawl-e ( Not bad )
The CRAWL-E developers are very familiar with how TCP and HTTP works and using that knowledge have written a web crawler intended to maximize TCP throughput. This benefit is realized when crawling web servers that utilize persistent HTTP connections as numerous requests will be made over a single TCP connection thus increasing the throughput.
#Squzer - missing in action
SuperCrawler - not bad but the code looks a bit terse.
Fseek
Fseek is a python-based web crawler. The user-interface is implemented using Django, the back-end uses pyCurl to fetch pages, and Pyro is used for IPC.
Says it's Django but it's not. I liked the idea of it being "presentation ready"... could be handy.
cannot create writable FSEEK_DATA_DIR /var/fseek.
ImportError: No module named Pyro.naming
failed to load external entity "/var/fseek/solr/etc/jetty.xml"
Needed Pyro
Webchuan ( XPathy)
Jazz crawler
Broke on unicode data (added any2ascii wrappers and it solved it -- hack)
Then borked on a draw_graph (probably too big)
Interesting because it builds a graph (and calculates PageRank) of the data gathered enabling an out-of-the-box simple visualisation...

Harvestman
I have used this before and found did "too powerful", I never did work out how to get it not to save crawled files to disk. I was unhappy with the config.xml approach to running the crawler too. If Scrapy proves unsuccessful I will return to this because it's a great product.
ExternalSiteCatalog - an integration of Harvestman with Plone - may be useful later.
AWCrawler - a python spider that saves data to Amazon S3 etc
Scrapy (XPath and pipelines)
Web crawlers are funny things. I have had a little experience of working with web crawlers in the past with a mixed set of results. Many were too difficult to configure or simply not robust enough. At this stage of the project, I would ideally like a crawler that is easy to adapt and yet trust-worthy enough to be able to set it running and leave it.
Imagining that I don't want to crawl very large portions of the internet, instead looking just to work with small corners I will be happy with something simple. Worth trialling are alternatives to "doing it yourself", such a Yahoo Pipes and the 80legs.com crawling service as well as Yahoo Boss search engine builder. Whenever possible I will consider using these tools, simply because of the time needed to crawl for data.
My preferred language is python but I wonder if there is a more web-centric language to think about? I vaguely remember Rebol as having URLs as base types. Maybe Rebol is worth exploring.
I started by looking at a list of python crawlers at Ohloh http://www.ohloh.net/p?sort=users&q=python+crawler and from these tested these....
Testing Notes...
Ruya (Not bad, has before_crawl and after_crawl functions that you overshadow)
Mechanize (Kind of browser simulation - including form filling)
import re from mechanize import Browser br = Browser() br.open("http://www.example.com/") # follow second link with element text matching regular expression response1 = br.follow_link(text_regex=r"cheese\s*shop", nr=1) assert br.viewing_html() print br.title() print response1.geturl()
Crawl-e ( Not bad )
The CRAWL-E developers are very familiar with how TCP and HTTP works and using that knowledge have written a web crawler intended to maximize TCP throughput. This benefit is realized when crawling web servers that utilize persistent HTTP connections as numerous requests will be made over a single TCP connection thus increasing the throughput.
#Squzer - missing in action
SuperCrawler - not bad but the code looks a bit terse.
Fseek
Fseek is a python-based web crawler. The user-interface is implemented using Django, the back-end uses pyCurl to fetch pages, and Pyro is used for IPC.
Says it's Django but it's not. I liked the idea of it being "presentation ready"... could be handy.
cannot create writable FSEEK_DATA_DIR /var/fseek.
ImportError: No module named Pyro.naming
failed to load external entity "/var/fseek/solr/etc/jetty.xml"
Needed Pyro
Webchuan ( XPathy)
WebChuan is a set of open source libraries and tools for getting and parsing web pages of website. It is written in Python, based on Twisted and lxml.
It is inspired by GStreamer. WebChuan is designed to be back-end of web-bot, it is easy to use, powerful, flexible, reusable and efficient.
Error in the setup.py script removed the description and it worked.
Jazz crawler
Broke on unicode data (added any2ascii wrappers and it solved it -- hack)
Then borked on a draw_graph (probably too big)
Interesting because it builds a graph (and calculates PageRank) of the data gathered enabling an out-of-the-box simple visualisation...
Harvestman
I have used this before and found did "too powerful", I never did work out how to get it not to save crawled files to disk. I was unhappy with the config.xml approach to running the crawler too. If Scrapy proves unsuccessful I will return to this because it's a great product.
ExternalSiteCatalog - an integration of Harvestman with Plone - may be useful later.
AWCrawler - a python spider that saves data to Amazon S3 etc
Scrapy (XPath and pipelines)
Scrapy is new (to me) and looks easy to modify. I will experiment with this, though will need to learn some XPath to begin with.
The Sprint Cycle

Sprint 1: The aim to to produce the simplest thing possible that is remotely useful. I will attempt (this week) to make a full traversal of the cycle. At this point I don't have the details of people's profile on social media sites (the survey hasn't been published yet), I don't have any real knowledge about worth with repositories, nor of working with LinkedData. I will need to work with what I have, namely the data that is already "out there"... web pages and links.
Whilst the aim may be to make something more like the Research Portal (shown below), this week is going to be all about doing something MUCH SIMPLER.

Aims
- Review crawling components (and mine York's existing data - wherever it is)
- Display content in a TagCloud
- Attempt to integrate with some LinkedData
- Attempt to present and data or relationships in a novel way
- Publish the Social Media Survey to hopefully find out more about what is being used at York.
The first iteration of the cycle looks like this. And nothing like thrashing around in frogspawn.

Milestone 1 Report
I have trialled a number of tools (SocialText, Jive, Elgg, Confluence, LifeRay Social Office and Cyn.in) with a number of teams which include...
... and although we now have 117 registered members, many of those are not particularly active... BUT many more are contributing to the discussion about the needs and directions of the project from a mixture of background, research, development, management, support and financial. The important thing is that the debate surrounding the project is happening in the project tool itself, and not hidden on email lists or password protected wikis.

The Social Media Survey is complete and awaiting publication. This will hopefully find sites that we don't know exist and the extent of the use of different tools at the university.

Thursday, 18 March 2010
Milestones
Milestone 1: People and Site
a. People. The first milestone is about assembling a team of people engaged with the as yet, non-existent PPPeople PPPowered technology. This team will provide the data, particularly their social media usage and profiles etc with which the initial data-mining can be built upon.
Goals: To have at least 20 people in a number of teams of people willing to work with me on the JISC project, providing hard data, usage and feedback.
b. Presentation. The data that is ultimately mined needs to be "hosted" in a software tool that provides a level of service that is valuable enough to be used frequently. This will ensure that meaningful relationships between people are presented and then subsequently pruned by participant. The choice for which tool we use at this point was initially between Wordpress, Drupal, Elgg and LifeRay.
The conceptual framing of what this tool should be, a people directory, a people discovery tool or a profile repository or a personal new aggregator is quite important with regards to setting expectations (for re-visiting the site)
Outcomes:
 This phase is very dependent on peoples' time availability and willingness to engage and also on the richness of the data returned from the survey. If nobody at all uses social media or completes the survey we won't have a lot to begin with.
This phase is very dependent on peoples' time availability and willingness to engage and also on the richness of the data returned from the survey. If nobody at all uses social media or completes the survey we won't have a lot to begin with.
Milestone 2: Just Data and Display

The first stages of displaying mined data with avoid the complexities of semantic reasoning about the data, about using unusual sources of data and begin by simply asking people to complete a survey. This will hopefully result in a spreadsheet of sites, blogs, social media memberships (twitter, linkedin, CiteULike etc) and will form the basis for exploring slightly less explicit data (connections in Linked in, followers on Twitter, mentions in Twitter or on other people's blogs.
To display this data, initially we will need to adapt the profile in the presentation tool, perhaps including an RSS aggregation.
Outcomes:
This will require a good understanding of the plug-in architecture of the presentation tool. The whole point of this project is to be integrated into a tool that is usable and used.
Milestone 3: More Deeply Mined Data
This stage looks to find information beyond that that is given, perhaps crawling Google searches, finding more distant links between resources. Ideally any crawling or querying tools should be well integrated into the presentation tool OR componentized and talk to the presentation tool via XMLRPC or similar.
We will experiment with (probably python-based) web-crawlers such as Domo, Harvestman, Mechanize and Scrapy. In addition we will look at free or low lost tools and services available. These may include...
Outcomes:
Whilst I am more than familiar with creating simple crawlers this will need a more standalone, robust, better architected approach.
SPARQL is very new to me. I need more understanding of RDF, LinkedData etc. Although the JISC Dev8D conference gave me new insights into the possibilities presented by LinkedData and open data I still feel I have a way to go to fully understand this area.

Need to understand more about the maths behind networks and visualisation. Luckily Gustav Delius is around to advise.
a. People. The first milestone is about assembling a team of people engaged with the as yet, non-existent PPPeople PPPowered technology. This team will provide the data, particularly their social media usage and profiles etc with which the initial data-mining can be built upon.
Goals: To have at least 20 people in a number of teams of people willing to work with me on the JISC project, providing hard data, usage and feedback.
b. Presentation. The data that is ultimately mined needs to be "hosted" in a software tool that provides a level of service that is valuable enough to be used frequently. This will ensure that meaningful relationships between people are presented and then subsequently pruned by participant. The choice for which tool we use at this point was initially between Wordpress, Drupal, Elgg and LifeRay.
The conceptual framing of what this tool should be, a people directory, a people discovery tool or a profile repository or a personal new aggregator is quite important with regards to setting expectations (for re-visiting the site)
Outcomes:
- To have a site up and running, available to staff at University of York that at least displays their profile in some way.
- A blog post reporting on the project so far, the plan, the tool chosen (with reasons) and invitations to help with the plan (which semantic repositorities to us (and how), which crawling tools to use
- Review the approaches take with other social networking sites to gather any useful approaches. For example, are their benefits to be gained by leveraging an existing social network and evangelising the use of a certain social network in order to ease data gathering.
 This phase is very dependent on peoples' time availability and willingness to engage and also on the richness of the data returned from the survey. If nobody at all uses social media or completes the survey we won't have a lot to begin with.
This phase is very dependent on peoples' time availability and willingness to engage and also on the richness of the data returned from the survey. If nobody at all uses social media or completes the survey we won't have a lot to begin with.Milestone 2: Just Data and Display

The first stages of displaying mined data with avoid the complexities of semantic reasoning about the data, about using unusual sources of data and begin by simply asking people to complete a survey. This will hopefully result in a spreadsheet of sites, blogs, social media memberships (twitter, linkedin, CiteULike etc) and will form the basis for exploring slightly less explicit data (connections in Linked in, followers on Twitter, mentions in Twitter or on other people's blogs.
To display this data, initially we will need to adapt the profile in the presentation tool, perhaps including an RSS aggregation.
Outcomes:
- A survey asking people to identify their social media accounts, interests in the form of keyword, URLs etc
- A site with at least 20 members showing their "simple" social media membership and some of the data (recent tweets, friends etc).
- The initial adaptation code (module/plugin) uploaded to the SVN site.
- A blog post showing developments and with comments from members.
This will require a good understanding of the plug-in architecture of the presentation tool. The whole point of this project is to be integrated into a tool that is usable and used.Milestone 3: More Deeply Mined Data
This stage looks to find information beyond that that is given, perhaps crawling Google searches, finding more distant links between resources. Ideally any crawling or querying tools should be well integrated into the presentation tool OR componentized and talk to the presentation tool via XMLRPC or similar.
We will experiment with (probably python-based) web-crawlers such as Domo, Harvestman, Mechanize and Scrapy. In addition we will look at free or low lost tools and services available. These may include...
- Yahoo Pipes - online data manipulation and routing
- 80 legs - a crawling service
- Maltego - a desktop open source forensics application
- Picalo - desktop forensics application (or any other tool)
Outcomes:
- More interesting data, richer connections
- A generic crawling methodology
Whilst I am more than familiar with creating simple crawlers this will need a more standalone, robust, better architected approach.Milestone 4: Semantified Data
This stage will look at how to apply semantic tools, or a more reasoned understanding of the data gathered. We will be looking at ...
- Yahoo Boss for general searching.
- OpenCalais, to attempt to discover entities in unstructured data
- DBPedia, Edina, Freebase for understanding entities like Towns, Universities, Concepts etc
- ePrints research repository to connect people via research outputs
SPARQL is very new to me. I need more understanding of RDF, LinkedData etc. Although the JISC Dev8D conference gave me new insights into the possibilities presented by LinkedData and open data I still feel I have a way to go to fully understand this area.Milestone 5: Slightly More Sophisticated Presentation
Depending on the data gathered, there will be opportunities to present the data in more interesting and usable ways. Initially we will attempt to use simple visualisations such as timelines, tree maps, word clouds etc. which can be easily integrated in the presentation tool.

More ambitious visualisations such as Mention Map example will be explored if appropriate.
Need to understand more about the maths behind networks and visualisation. Luckily Gustav Delius is around to advise.Tuesday, 16 March 2010
Basic Plan

This shows the basic plan for the project. The hope is that the first run of this process should be complete as soon as is possible. This means that the REASONING and VISUALISATION stage may be omitted, where the the data can be presented as a simple list.
This makes the choice for the DATA-GATHERING and PRESENTATION tools very important. We want them to be very well integrated. Ironically, given the importance of the PRESENTATION stage, namely what user profile data it stores (social media usernames etc), what features it supports (RSS aggregation, Twitter presentation, Plugin development opportunities etc).
Saturday, 6 March 2010
Subscribe to:
Posts (Atom)

